Tokens và Tokenization: Nền Tảng Của AI Trong Xử Lý Dữ Liệu Văn Bản, Ảnh, và Audio
Khi nhắc đến cách các mô hình AI hoạt động, tokens và tokenization là hai khái niệm quan trọng mà chúng ta cần hiểu. Đây là nền tảng giúp AI xử lý và hiểu dữ liệu từ văn bản, hình ảnh, đến âm thanh. Dù là GPT-4 xử lý câu chữ, Vision Transformer phân tích hình ảnh, hay Whisper chuyển giọng nói thành văn bản, tất cả đều dựa trên cách token và tokenization hoạt động.
Tokens Là Gì?
Tokens là các đơn vị nhỏ nhất mà mô hình AI sử dụng để hiểu và xử lý dữ liệu.
Với văn bản, tokens có thể là từ, phần của từ, hoặc ký tự.
Với hình ảnh, tokens là các mảnh nhỏ của ảnh, gọi là patches.
Với âm thanh, tokens là các khung thời gian hoặc đặc trưng âm thanh.
Ví dụ:
Văn bản: "Trí tuệ nhân tạo" → ["Trí", "tuệ", "nhân", "tạo"].
Ảnh: Một bức ảnh 256x256 pixel được chia thành các patch 16x16 pixel.
Âm thanh: Một đoạn sóng âm thanh 10 giây được chia thành các khung thời gian nhỏ 20ms.

Tokenization Là Gì?
Tokenization là quá trình chuyển đổi dữ liệu thô (văn bản, hình ảnh, hoặc âm thanh) thành các token để mô hình AI có thể xử lý. Đây là bước đầu tiên và quan trọng trong mọi hệ thống AI.
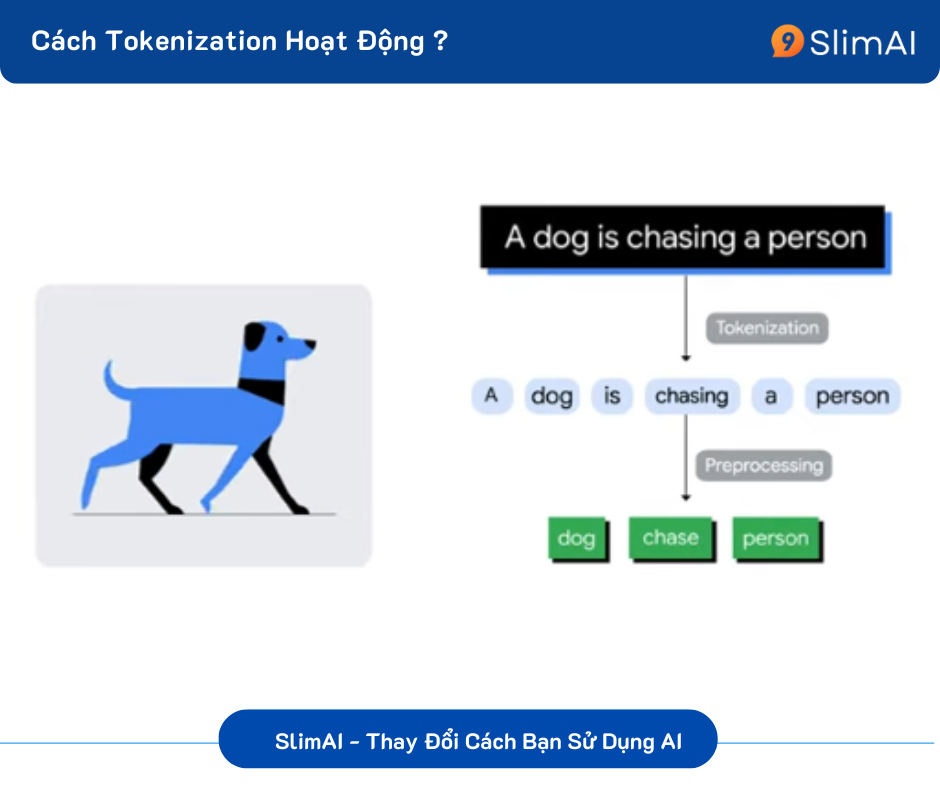
Cách Tokenization Hoạt Động:
Văn bản (Text):
- Token hóa dựa trên từ, khoảng trắng, hoặc sử dụng kỹ thuật byte-pair encoding (BPE) để chia nhỏ từ thành các phần.
- Ví dụ: "unbelievable" →
["un", "believ", "able"].
Hình ảnh (Image):
Ảnh được chia thành các mảnh nhỏ (patch), sau đó mỗi patch được chuyển thành vector số.
Ví dụ: Một ảnh 256x256 pixel → chia thành 16x16 patch → mỗi patch trở thành 1 token.
Âm thanh (Audio):
Ứng Dụng Của Tokens và Tokenization Trong AI
1. Văn Bản
Tokens: Là từ, ký tự, hoặc phần của từ.
Ứng dụng: GPT-4, BERT dùng token để tạo nội dung, trả lời câu hỏi, hoặc phân tích văn bản.
Giới hạn token: GPT-4 có thể xử lý tối đa 32.000 token, tương đương với một bài luận dài khoảng 50 trang.
2. Hình Ảnh
Tokens: Là các patch hoặc pixel từ ảnh.
Ứng dụng: Vision Transformer (ViT) sử dụng tokens để nhận diện đối tượng hoặc tạo hình ảnh mới (như DALL-E).
Lợi ích: Phân tích chi tiết, giúp AI hiểu cấu trúc và nội dung của ảnh.
3. Âm Thanh
Tokens: Là các khung thời gian hoặc đặc trưng âm thanh.
Ứng dụng: Whisper (OpenAI) chuyển giọng nói thành văn bản, còn Tacotron tạo giọng nói từ văn bản.
Lợi ích: Xử lý âm thanh nhanh chóng, chính xác, từ nhận dạng giọng nói đến tổng hợp giọng nói.
Sự Khác Biệt Giữa Tokenization Trong Văn Bản, Ảnh, và Audio
| Yếu tố | Văn bản | Hình ảnh | Âm thanh |
|---|
| Đơn vị token | Từ, ký tự, hoặc phần của từ | Patch (ví dụ: 16x16 pixel) | Frame hoặc đặc trưng âm thanh (MFCC, Spectrogram). |
| Tokenization | Dựa trên khoảng trắng, BPE, hoặc các kỹ thuật khác. | Chia ảnh thành patches. | Chia nhỏ sóng âm và trích xuất đặc trưng. |
| Ứng dụng chính | Xử lý ngôn ngữ tự nhiên, dịch thuật, sáng tạo nội dung. | Nhận diện hình ảnh, tạo hình ảnh mới. | Nhận dạng giọng nói, tạo giọng nói. |
Thách Thức Trong Tokenization
Dữ liệu lớn: Hình ảnh và âm thanh thường có kích thước lớn hơn văn bản, đòi hỏi tài nguyên tính toán cao.
Mất mát thông tin: Việc chia nhỏ dữ liệu có thể dẫn đến mất chi tiết quan trọng nếu không tối ưu hóa.
Phức tạp hơn với đa ngôn ngữ: Đối với văn bản đa ngôn ngữ, việc token hóa phải xử lý các ngôn ngữ có cấu trúc khác nhau (như tiếng Việt và tiếng Nhật).
Tại Sao Tokens và Tokenization Quan Trọng?
Hiệu suất xử lý: Tokenization giúp mô hình xử lý dữ liệu nhanh hơn, chính xác hơn.
Tối ưu hóa prompt: Hiểu rõ giới hạn token giúp người dùng tạo prompt hiệu quả hơn khi làm việc với mô hình AI như GPT-4.
Ứng dụng đa dạng: Từ xử lý ngôn ngữ, nhận diện hình ảnh, đến xử lý âm thanh, mọi lĩnh vực AI đều cần token và tokenization.
Giới Hạn Token Và Ứng Dụng
Các mô hình AI có giới hạn token cụ thể, ảnh hưởng trực tiếp đến độ dài văn bản hoặc dữ liệu mà chúng có thể xử lý.
1. Giới hạn token của các mô hình AI phổ biến:
2. Quy đổi token thành từ:
Trung bình, 1 token ≈ 4 ký tự tiếng Anh hoặc 3 ký tự tiếng Việt, bao gồm cả dấu cách và dấu câu.
Lưu ý rằng ký tự trên mỗi token tiếng Việt thấp hơn, vì tiếng Việt thường ngắn gọn và sử dụng nhiều từ đơn. Nhưng số lượng token cho cùng một đoạn văn tiếng Việt sẽ nhiều hơn so với tiếng Anh. Bạn có thể kiểm chứng chi tiết bằng công cụ Tokenizer của OpenAI
Ví dụ:
3. Ứng dụng của giới hạn token:
Tối ưu prompt: Đảm bảo các yêu cầu gửi đến mô hình không vượt quá giới hạn token.
Xử lý văn bản dài: Với các tài liệu dài hơn giới hạn, bạn có thể chia nhỏ thành nhiều phần để xử lý.
Kết Luận
Tokens và tokenization là nền tảng của mọi hệ thống AI, từ xử lý văn bản, hình ảnh, đến âm thanh. Hiểu rõ cách chúng hoạt động giúp bạn tối ưu hóa hiệu suất khi làm việc với AI, đồng thời mở ra nhiều ứng dụng trong các lĩnh vực khác nhau. Với sự phát triển của các mô hình AI hiện đại, vai trò của tokens và tokenization ngày càng trở nên quan trọng hơn bao giờ hết.